Sunday, August 17, 2025
Is It Possible to Get Depth from a Single Image? How Apple's Depth Pro Estimates Depth
Posted by

Special thanks to those who inspired and supported this post:
Murat Gülhan, Muharrem Aytekin, and Hakan Yıldırım
Introduction: The Challenge of Depth from a Single Image
Depth estimation from a single image is one of the most fascinating challenges in computer vision. Unlike humans who can perceive depth through various visual cues, computers struggle to understand the three-dimensional world from a flat, two-dimensional image.
3D World Coordinates vs. 2D Image Coordinates
In computer vision, we often represent points in the 3D world and their projections onto a 2D image using matrices:
3D World Point (Homogeneous Coordinates)
A point in 3D space is represented as a column vector:
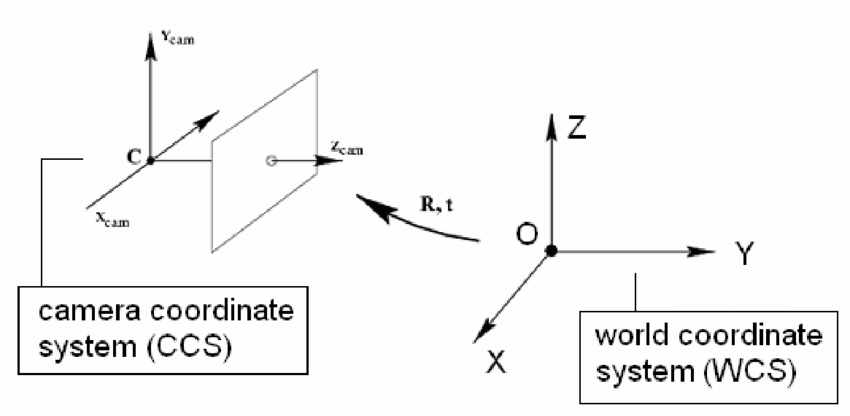
Reference: Tola, Engin. (2005). Multi-view 3D Reconstruction of a Scene Containing Independently Moving Objects.
Where:
- X, Y, Z: 3D world coordinates
- 1: Homogeneous coordinate (for matrix operations)
In homogeneous coordinates, this is represented as:
2D Image Point (Homogeneous Coordinates)
A point in the 2D image is represented as a column vector:
Where:
- u, v: 2D image coordinates (pixels)
- 1: Homogeneous coordinate
Projection Matrix (P)
A camera projects a 3D point onto a 2D image plane. This is represented with a projection matrix:
P =
Where:
- P: 3×4 projection matrix that combines intrinsic and extrinsic parameters
- fx, fy: Focal lengths in pixels
- cx, cy: Principal point coordinates
- Last column: All zeros for perspective projection (no translation in image plane)

The projection matrix P = K × [R | t] combines both the camera's intrinsic parameters (K) and extrinsic parameters (rotation and translation) into a single 3×4 matrix that directly maps 3D world points to 2D image coordinates.
Note:
Understanding Camera Parameters
Intrinsic Parameters (Camera Internal Properties)
Focal Length (fₓ, fᵧ):
- What it is: The distance between the camera's optical center and the image sensor
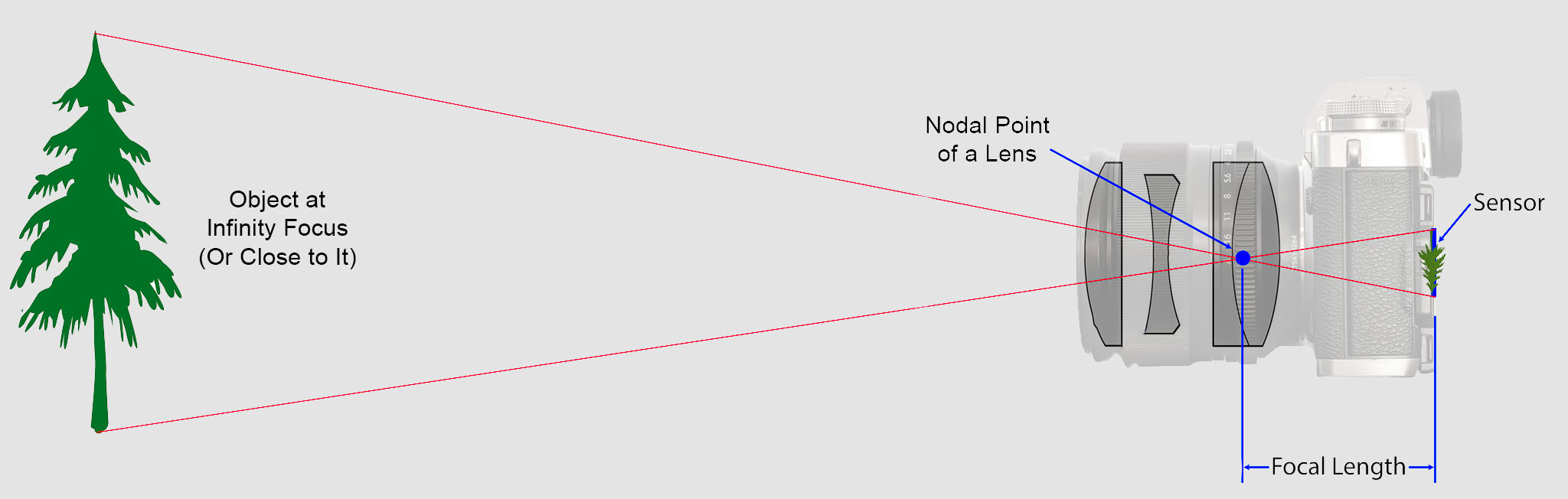
- Physical meaning: Determines how much the camera "zooms in" - longer focal length = more zoom
- Units: In the real world, a lens has a physical focal length (e.g., 35 mm). But when mapping 3D world coordinates to a digital image, the image plane is made of pixels. So, we convert the physical focal length (in millimeters) into pixels using the camera’s sensor size and the pixel pitch (the size of each pixel). Thus, focal length is measured in pixels (not millimeters) when working in image coordinates.
- Why two values: fₓ for horizontal, fᵧ for vertical (accounts for non-square pixels)
Principal Point Coordinates (cₓ, cᵧ):
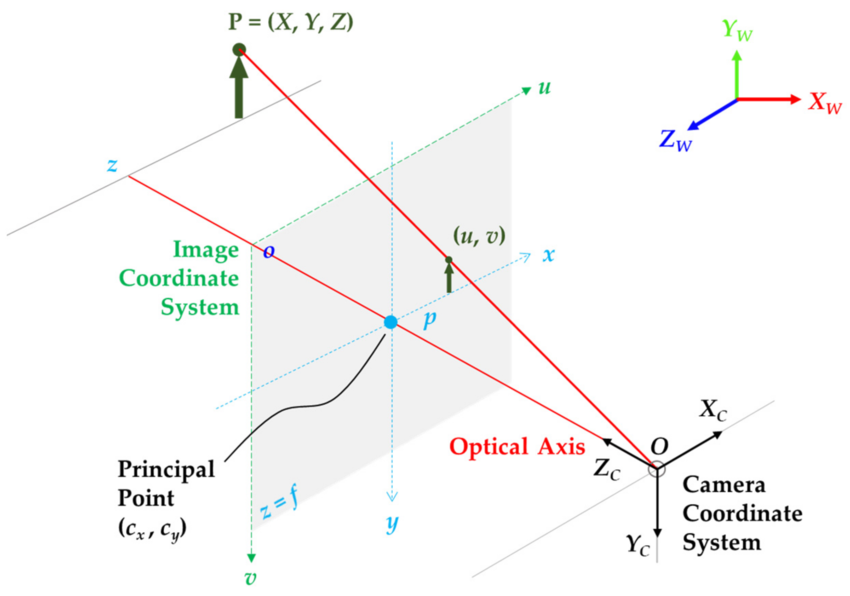
Reference: Yeong, De Jong & Velasco-Hernandez, Gustavo & Barry, John & Walsh, Joseph. (2021).
Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors. 21. 2140. 10.3390/s21062140.
- What it is: The intersection point of the optical axis with the image plane
- Physical meaning: The center of the image sensor (usually the image center)
- Units: Pixels from the top-left corner of the image
- Typical values: cₓ = image_width/2, cᵧ = image_height/2 (for centered sensors)
- Why important: Accounts for manufacturing imperfections where the optical center isn't exactly at the image center
Extrinsic Parameters (Camera Position and Orientation)
Rotation Matrix (R):
- **3×3 matrix describing how the camera is oriented in 3D space
- Properties: Orthogonal matrix (R^T × R = I), determinant = 1
- **Can be expressed as Euler angles, quaternions, or rotation vectors
Translation Vector (t):
- *3×1 vector describing the camera's position in 3D space
Why Single-Image Depth is Challenging
Estimating depth from a single image is fundamentally challenging because, unlike stereo vision (which uses two images from slightly different viewpoints), a single image does not provide direct geometric cues about how far objects are from the camera. The 3D world is projected onto a 2D plane, causing loss of depth information.
u = fx × (Xc / Zc) + cx, v = fy × (Yc / Zc) + cy
Here, (Xc, Yc, Zc) are the 3D coordinates of a point in the camera coordinate system, (u, v) are the corresponding pixel coordinates in the image, fx and fy are the focal lengths in pixels, and (cx, cy) are the principal point offsets.
Why can't we get depth from a single image?
From a single image, we only observe (u, v), but both Xc and Zc (or Yc and Zc) are unknown. This means that there are infinitely many 3D points that could correspond to the same pixel; therefore, the depth Zc cannot be determined directly.
Stereo Cameras for More Accurate Depth
While single-image depth estimation is impressive, using two cameras—known as a stereo camera setup—can provide much more accurate depth information. Stereo vision mimics human binocular vision: two cameras are placed a fixed distance apart (the "baseline") and capture images of the same scene from slightly different viewpoints.
How can we estimate depth with two images (stereo)?
With two images taken from slightly different viewpoints (a stereo pair), we can find the same point in both images and measure its horizontal displacement, called disparity (d). For rectified stereo images, the depth Zc can be computed as:
Stereo Geometry: Depth Calculation
Consider two cameras: left (L) and right (R), separated by a distance called the baseline (B).
- The left camera center: OL
- The right camera center: OR, shifted by B along the x-axis.
For a 3D point:
- In the left camera: XL = X, Zc = Z
- In the right camera: XR = X - B, Zc = Z
Image projections:
- Left image: uL = f × (X / Z)
- Right image: uR = f × ((X - B) / Z)
Disparity (d): The horizontal difference between the same point in both images:
d = uL - uR = (f × B) / Z
Solving for depth (Z):
Z = (f × B) / d
This formula summarizes how stereo cameras compute real depth.
Zc = (f × B) / d
where:
- f is the focal length (in pixels),
- B is the baseline (distance between the two camera centers),
- d is the disparity (difference in u coordinates between the left and right images).
By matching corresponding points and measuring disparity, we can triangulate the true depth of each point in the scene.
How Stereo Depth Works:
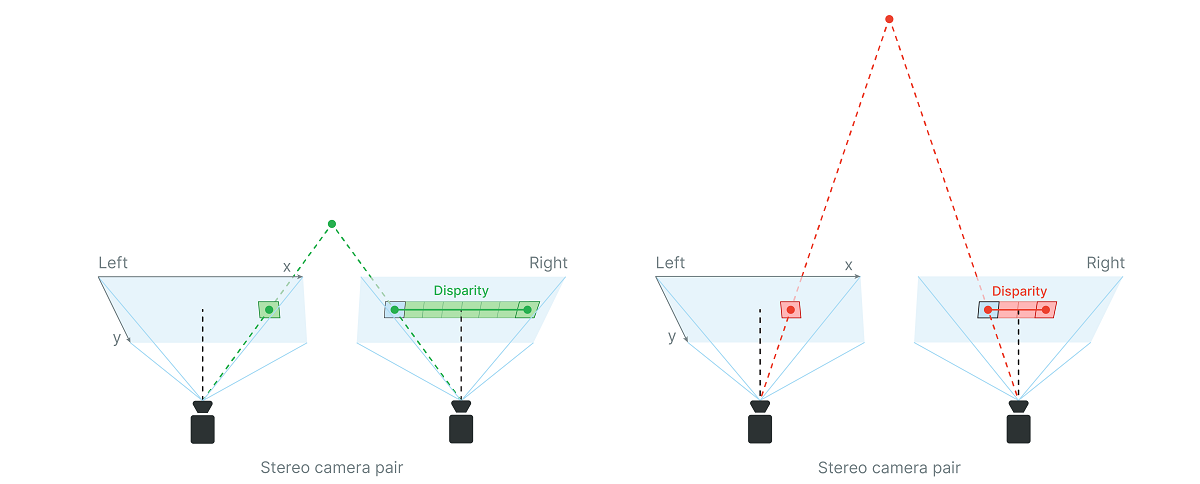
Reference: Luxonis Docs: Configuring Stereo Depth
- By comparing the positions of the same feature in both images (called "disparity"), we can triangulate the actual distance to that feature.
- The greater the disparity (difference in position), the closer the object is to the cameras.
- This geometric approach provides direct, metric depth measurements, unlike single-image methods that rely on learned cues and priors.
Alternative: Depth from Multiple Frames (Structure from Motion)
While stereo cameras use two lenses to capture depth, you can also estimate depth using a single moving camera by capturing multiple frames from different viewpoints. This technique is known as Structure from Motion (SfM) or Multi-View Geometry.
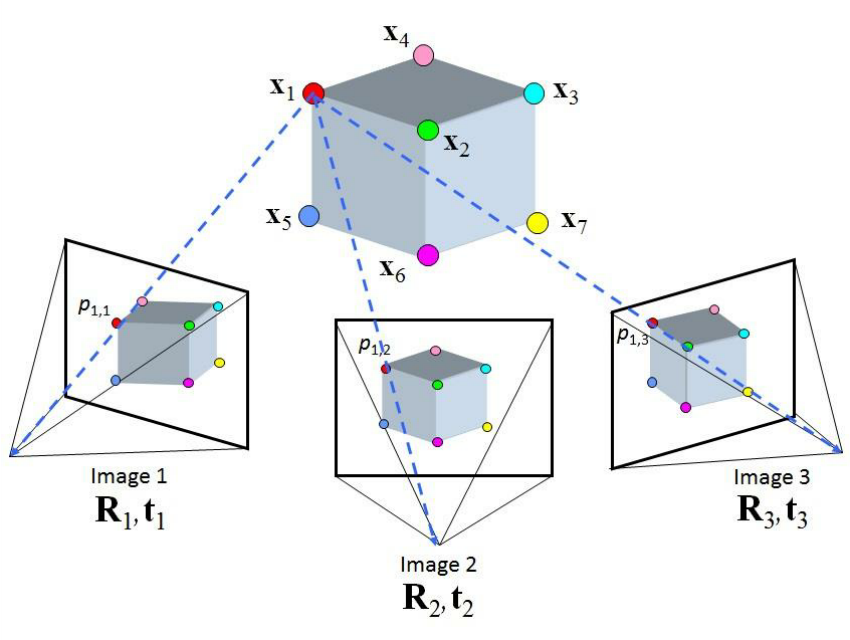
Reference: Yilmaz, Ozgur & Karakus, Fatih. (2013). Stereo and kinect fusion for continuous 3D reconstruction and visual odometry. 115-118. 10.1109/ICECCO.2013.6718242
- Key idea: If you move a camera (for example, by walking with your phone or flying a drone), each frame provides a slightly different view of the scene. By tracking how features move between frames, you can triangulate their 3D positions—just like with two cameras, but using time-separated images instead of two simultaneous ones.
- Depth from motion: The more the camera moves (with known motion), the more accurate the depth estimation can be, as long as there is enough parallax (change in viewpoint).
How it works:
- Detect and track feature points across multiple frames.
- Estimate the camera's motion between frames (using visual odometry or IMU data).
- Triangulate the 3D position of each feature using the known camera poses and the observed 2D positions.
Applications:
- Used in 3D Mapping, AR/VR, and robotics.
Depth Estimation with Drones
Drones are a practical example of using multiple frames for depth estimation:
- As a drone flies, its onboard camera captures a sequence of images from different positions.
- By analyzing how features move across these frames, the drone can build a 3D map of its environment.
- This is crucial for tasks like obstacle avoidance, autonomous navigation, and mapping.

Advantages:
- No need for two cameras—just a single camera and motion.
- Works in environments where stereo setups are impractical.
Apple's Depth Pro Model: Zero-Shot Metric Monocular Depth Estimation
Note:
All information in this section is based on the following article:
Bochkovskii, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S. R., & Koltun, V. (2025). Depth Pro: Sharp Monocular Metric Depth in Less Than a Second. arXiv preprint arXiv:2410.02073. https://arxiv.org/abs/2410.02073
Apple's Depth Pro is a new foundation model for zero-shot metric monocular depth estimation. In other words, given a single RGB image, Depth Pro produces a high-resolution, per-pixel depth map in real-world units (meters)—without needing any camera metadata.

Key highlights:
- No camera metadata required: Depth Pro can infer the camera's field-of-view (focal length) directly from the image, so it works even when EXIF data is missing.
- High speed and resolution: On modern GPUs, it processes a 1536×1536 image (~2.3 MP) in about 0.3 seconds, producing sharp, high-frequency detail (e.g., fine hair and object edges).
- Metric depth (with caveats): Produces depth maps in real-world units (meters), but the absolute accuracy can vary depending on scene type, camera properties, and image content (see discussion below).
Note:
While Apple's Depth Pro model estimates per-pixel depth and focal length from a single image, its primary purpose is not to deliver perfectly accurate or 100% reliable metric depth. Instead, the model excels at understanding relative depth differences between objects in an image and segmenting objects from the background. This enables a wide range of multi-purpose applications across the Apple ecosystem, such as copying or isolating objects from photos in macOS and iPhone, AR experiences, and enhanced photo editing. The focus is on robust, generalizable depth and object separation, rather than absolute precision.
Core Innovations
- Multi-scale Vision Transformer (ViT) Architecture:
Depth Pro uses an efficient, patch-based ViT backbone that fuses information at multiple scales for dense, high-resolution prediction.
Note:
A "Multi-scale Vision Transformer (ViT) Architecture" means that the model processes the input image at several different resolutions (scales) to capture both fine details and the overall scene structure. Here’s how it works in Depth Pro:
-
Input and Patch Splitting:
- The input image is resized to 1536×1536 pixels.
- The image is split into small square patches (like tiles), and each patch is embedded and processed by a Vision Transformer (ViT).
-
Multi-Scale Processing:
- The image is analyzed at multiple scales:
- High resolution: Captures fine details (like hair, object edges).
- Lower resolutions: Captures the global layout and context of the scene.
- Each scale is processed by its own ViT, extracting features at that particular level of detail.
- The image is analyzed at multiple scales:
-
Global Context Branch:
- A smaller version of the image (e.g., 384×384) is also processed by a separate ViT to provide a "global view" of the scene, helping the model understand the overall context.
-
Fusion and Decoding:
- Features from all scales (local and global) are merged together using a decoder network (similar to U-Net or DPT architectures).
- This decoder combines the information to reconstruct a dense, high-resolution depth map.
-
Analogy:
- Think of it like solving a jigsaw puzzle:
- You first look at the big pieces to get the general picture (low resolution).
- Then you focus on the small pieces for fine details (high resolution).
- By combining both, you get a complete, detailed image.
- Think of it like solving a jigsaw puzzle:
In summary:
The multi-scale ViT architecture allows Depth Pro to produce sharp, detailed depth maps by leveraging both local details and the global scene context—all from a single image.
- Focal-Length Estimation Head:
A dedicated network head predicts the camera's focal length (field-of-view) from the image itself, enabling metric depth estimation without any external camera parameters.
Training Objectives
Depth Pro predicts canonical inverse depth (1/distance) which emphasizes nearby objects. The main loss function (LMAE) measures prediction accuracy while ignoring the worst 20% of pixels in real-world datasets.
Additional loss functions for sharp boundaries:
- LMAGE: Measures edge accuracy
- LMALE: Measures smoothness
- LMSGE: Measures edge precision
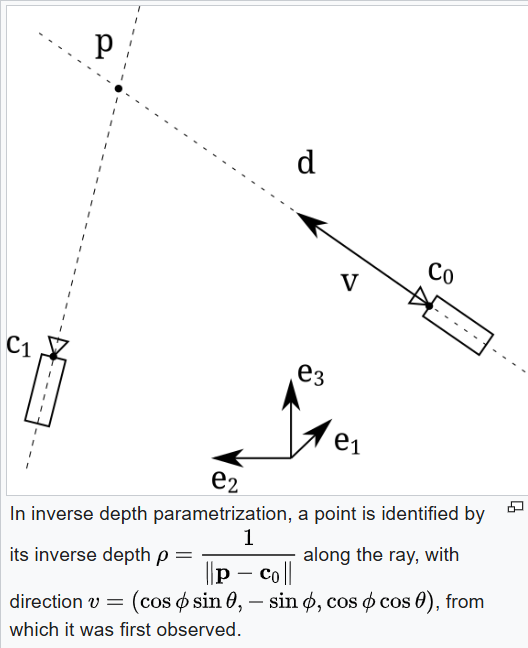
Reference: Inverse depth parametrization (Wikipedia)
This approach produces depth maps with sharp details and smooth transitions.
Training Curriculum
Depth Pro uses a two-stage approach:
Stage 1: Train on mixed datasets (real + synthetic) using LMAE loss for robustness Stage 2: Train only on synthetic data using multiple loss functions (LMAE, LMAGE, LMALE, LMSGE) for sharp boundaries
Note:
Why synthetic data last? Unlike common practice, Depth Pro trains on synthetic data in the final stage because real-world datasets often contain missing areas and blurry boundaries. Synthetic data provides pixel-perfect depth information for learning sharp object boundaries.
Evaluation Metrics for Sharp Boundaries
Uses existing annotations (segmentation, saliency, matting) to measure boundary sharpness:
- Compares neighboring pixels for depth differences (5-25% thresholds)
- Calculates precision/recall vs. ground truth
- No manual annotation needed and scale-invariant
This ensures sharp, accurate boundaries for real-world applications.
Focal Length Estimation
How does Depth Pro handle missing camera information?Since many images lack accurate EXIF metadata (camera information), Depth Pro includes a focal length estimation head that predicts the camera's field of view directly from the image content.
How It Works
- A small convolutional network analyzes the image to predict the horizontal angular field-of-view
- Uses frozen features from the depth estimation network plus task-specific features from a separate ViT encoder
- Trained separately from the main depth network to avoid balancing multiple objectives

Drag and drop your own images to estimate depth using Apple's Depth Pro model.
Try it on Hugging Face (opens in new tab)