GPU Efficient - Scalable, PCIe Friendly Multistream Licence Plate Recognition Pipeline
How we rebuilt an industrial licence plate recognition pipeline from a per-camera DeepStream architecture into a GPU-efficient, PCIe-friendly multistream design with batched OCR.

Overview
This article documents a production journey: taking a licence plate recognition (LPR) system that worked on a handful of cameras and rebuilding it for industrial scale — without pinning a single datacenter GPU at 94% utilization.
The original stack was not broken. On two cameras it was stable, accurate, and easy to operate. The problems surfaced only at scale, and they were architectural — not model-quality issues. The fix was not swapping OCR models; it was redesigning how video, detection, cropping, and recognition share GPU memory and PCIe bandwidth.
Part 1 covers the initial pipeline. Part 2 documents the rebuild and what each optimization contributed.
1. The Initial Pipeline
The production system was a DeepStream-based Docker service started with a single command:
python3 plate_supervisor.py -f plate_cams.txt
Behind that line hid a simple rule: one independent processing stack per camera.
Architecture
| Component | Role |
|---|---|
plate_supervisor.py | Reads plate_cams.txt and spawns one worker process per camera |
plate_ws_service.py | Per-camera pipeline: RTSP → YOLO TRT → crop → OCR → WebSocket |
plate_cams.txt | Camera registry — up to 20 streams in production |
manual_ocr_gateway.py | Gateway for on-demand manual OCR across cameras |
ocr-gpu-service | Separate container — PaddleOCR GPU over HTTP (POST /ocr) |
Each RTSP source got its own plate_ws_service.py OS process with a dedicated HTTP/WebSocket endpoint. DeepStream ran on a daemon thread inside that process; FastAPI/Uvicorn handled the API layer on the main asyncio loop.
plate_cams.txt (20 cameras)
│
▼
plate_supervisor.py
│
├── plate_ws_service.py (cam 1) ──► DeepStream + YOLO ──► HTTP OCR
├── plate_ws_service.py (cam 2) ──► DeepStream + YOLO ──► HTTP OCR
├── ...
└── plate_ws_service.py (cam 20) ──► DeepStream + YOLO ──► HTTP OCR
│
▼
ocr-gpu-service
(shared PaddleOCR API)
The system was multistream only in name. There was no shared nvstreammux across cameras — each stream owned its own OS process, its own DeepStream pipeline, its own YOLO TensorRT engine, and its own GPU context.
How a Frame Moved Through the System
NVIDIA DeepStream chains GStreamer elements to keep video on the GPU: NVDEC decode → nvstreammux → nvinfer (TensorRT) → Python probe. In our setup, nvstreammux was meant to batch multiple streams into one tensor, and nvinfer ran YOLO plate detection and attached bbox metadata (NvDsObjectMeta) to each frame. OCR lived outside DeepStream in a separate PaddleOCR service.
The per-camera path looked like this:
RTSP → NVDEC decode (GPU)
→ nvstreammux (batch-size = 1)
→ YOLO TensorRT — full-frame detection (GPU)
→ probe: full frame copied to CPU → crop sliced on CPU
→ JPEG encode → HTTP POST → PaddleOCR (det → cls → rec)
→ WebSocket result
YOLO always ran on the full decoded frame. The probe pulled the entire image out of GPU memory and only then cut the plate region on the CPU:
n_frame = pyds.get_nvds_buf_surface(hash(gst_buffer), frame_meta.batch_id)
frame_rgba = np.asarray(n_frame).copy() # GPU → CPU (full 1920×1080)
frame_bgr = cv2.cvtColor(frame_rgba, cv2.COLOR_RGBA2BGR)
crop = frame_bgr[py:py2, px:px2] # bbox slice on CPU, not GPU
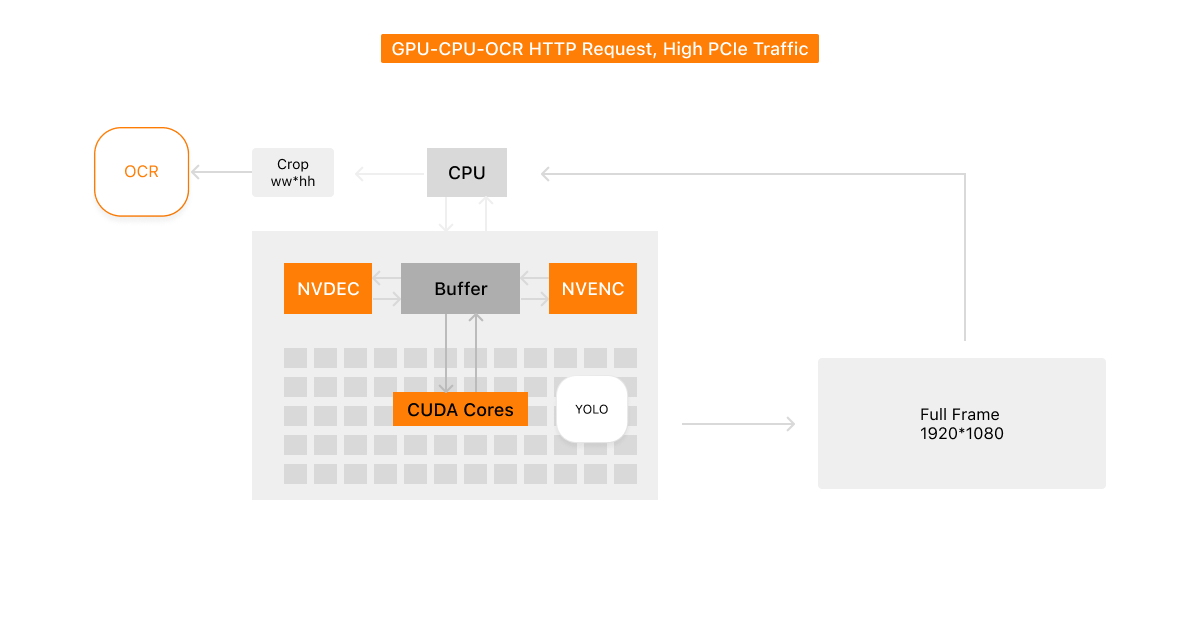
GPU–CPU–OCR HTTP request, high PCIe traffic — detection stays on the GPU; the bus carries the full frame even though only a small crop reaches OCR.
Diagram source: NVIDIA DeepStream — Gst-nvinfer plugin
Plate Detection: DeepStream Integration and the Batch-Size = 1 Ceiling
Standard DeepStream nvinfer cannot run Ultralytics YOLO out of the box. We used marcoslucianops/DeepStream-Yolo — a custom libnvdsinfer_custom_impl_Yolo.so that provides NvDsInferYoloCudaEngineGet (ONNX → TensorRT) and NvDsInferParseYolo (raw output → bounding boxes).
Thanks to Marcos Luciano for DeepStream-Yolo.
The YOLO engine was exported and configured at batch-size=1:
[property]
onnx-file=tr_plateV1.onnx
model-engine-file=plate_yolo.engine
batch-size=1
parse-bbox-func-name=NvDsInferParseYolo
custom-lib-path=.../libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
streammux.set_property("batch-size", 1)
pgie.set_property("config-file-path", PGIE_CONFIG_PATH)
With 20 cameras that meant 20 separate TensorRT engines in VRAM, each processing one frame per kernel launch. The GPU stayed busy (~94% utilization) firing small single-frame inferences across parallel pipelines — hard work, not smart work.
When we later tried true multistream, DeepStream logged Backend has maxBatchSize 1 whereas 2 has been requested. The ONNX had been exported at fixed batch=1 ([1, 3, 640, 640]); only a fixed-batch re-export (yolo export batch=N dynamic=False) could raise the ceiling.
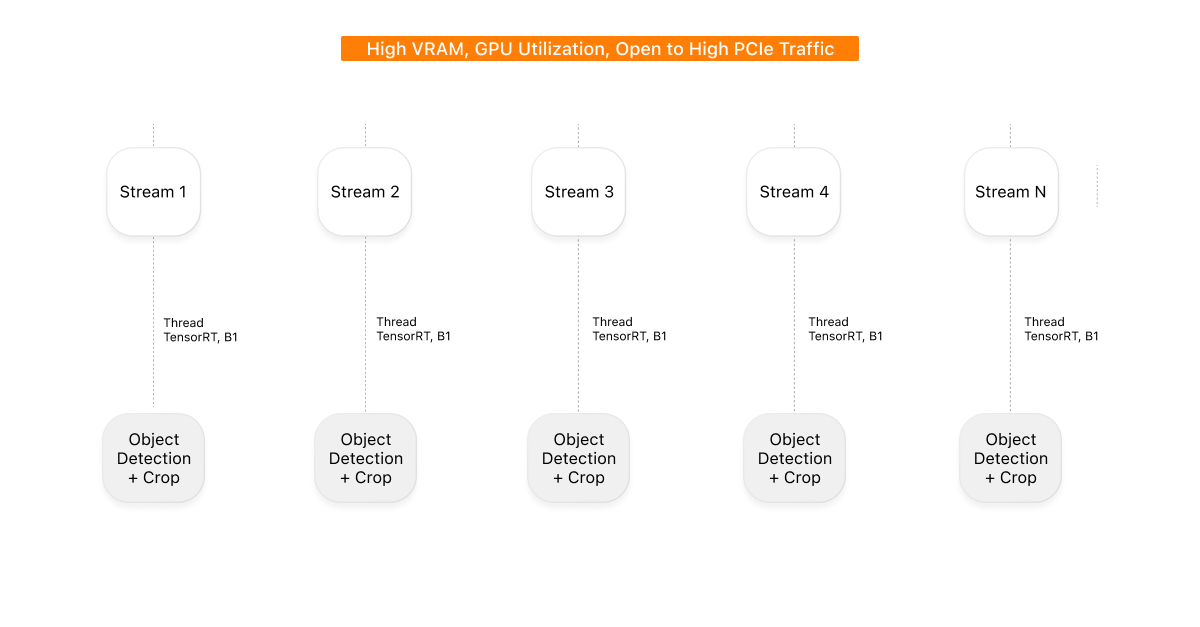
Each stream owns its own TensorRT thread (B1), its own engine in VRAM, and its own full-frame path. Frames from different cameras never enter the model as one batch.
Note — detector choice is not locked to YOLO. This deployment used YOLO for plate object detection, but DeepStream's
nvinferpath is model-agnostic at the integration layer: any PyTorch or TensorFlow detector exported to ONNX with a fixed or dynamic batch dimension compatible with TensorRT can replace it, provided a matching custom bbox parser (or standard detector output format) is wired intoconfig_plate_pgie.txt. The multistream architecture — sharednvstreammux, batched TRT engine, lazy ROI probe — does not depend on YOLO specifically.RF-DETR is a notable alternative. Core models (Nano through Large) ship under Apache 2.0, which simplifies commercial and redistribution use compared with some YOLO licensing paths. RF-DETR exports to ONNX (
model.export(format="onnx")) and integrates with DeepStream via community parsers such as deepstream-rfdetr — the samenvinfer+ customparse-bbox-func-namepattern as DeepStream-Yolo. For greenfield LPR projects where licence clarity and transformer-based accuracy matter, RF-DETR is worth evaluating alongside YOLO before committing to a TRT export.
OCR: Paddle GPU, Fast per Image, Slow at Fleet Scale
OCR ran in ocr-gpu-service (paddlecloud/paddleocr:2.6-gpu), a separate container exposing POST /ocr:
PaddleOCR(
use_angle_cls=True,
use_gpu=True,
det_model_dir="/models/en_PP-OCRv3_det_infer",
rec_model_dir="/models/en_PP-OCRv4_rec_infer",
cls_model_dir="/models/ch_ppocr_mobile_v2.0_cls_infer",
)
For a single cropped plate, performance was excellent — 27.ZE 822 at ~0.88 confidence, inferenceMs in the 40–55 ms range:
{ "mergedText": "27.ZE 822", "inferenceMs": 53.9 }
Two or three cameras sending occasional crops was no problem. The pain started when crop volume exceeded what a single-image service could drain: one HTTP request per crop, no batch endpoint, no dynamic batching — each call a standalone PaddleOCR.ocr(image, cls=True) processed largely one after another.
| Fleet size | What happened |
|---|---|
| 2–3 cameras | Sporadic crops, sub-second end-to-end |
| 20 cameras | Concurrent HTTP bursts, OCR queue forms |
| 30 cameras × 25 FPS | Far beyond single-image throughput |
inferenceMs stayed in the millisecond band, but queued requests waited seconds. And YOLO had already found the plate — yet PaddleOCR still ran full det → cls → rec on every crop.
What Worked, What Didn't
On a small fleet, the design had genuine strengths: per-camera fault isolation, simple onboarding (one line in plate_cams.txt), accurate OCR on single crops, and the right idea of cropping before OCR:
OCR_URL = "http://ocr-service.internal/ocr"
session.post(OCR_URL, files={"image": ("plate.jpg", jpeg_bytes, "image/jpeg")}, data={"lang": "en"})
At 20 cameras on one datacenter GPU, four structural limits collided:
| Limit | What it meant |
|---|---|
| Isolated pipelines | 20 processes × batch-1 YOLO engines in VRAM, no cross-camera batching |
| PCIe round-trip | Full frame GPU→CPU every probe tick, crop back to GPU for OCR |
| Monolithic OCR | PaddleOCR.ocr() det+cls+rec, no GPU batching |
| HTTP hot path | One crop per request into one PaddleOCR instance sharing GPU with 20 YOLO pipelines |
The service kept running. GPU utilization hit ~94%. But there was no headroom for burst traffic, new models, or fleet expansion.
Where We Headed Next
The rebuild would keep what worked — YOLO plate detection, crop-then-OCR, Docker deployment — and fix what blocked scale:
- Replace per-camera processes with true multistream batching (
nvstreammux). - Keep tensors on the GPU through crop and into OCR.
- Upgrade OCR to Paddle 3.x with real GPU batching.
- Replace monolithic
PaddleOCR.ocr()with a modular det→rec pipeline that still localizes text inside each YOLO crop.
2. The Rebuild
Four changes addressed the four limits from Part 1. Each maps to a concrete code path.
| Part 1 limit | Fix | Primary code |
|---|---|---|
| Isolated pipelines | Single multistream DeepStream service | plate_multistream_service.py |
| PCIe round-trip | Lazy ROI crop on unified GPU buffers | plate_ws_service.py (shared helpers) |
| Monolithic OCR, no batch | Paddle 3.x modular det→rec + GPU batch | ocr-gpu-v3 (ocr_service.py) |
| HTTP hot path | Client-side batch collector + POST /ocr/batch | plate_multistream_service.py + OCR service |
The entrypoint changed from a process supervisor to a single multistream daemon:
# Before
python3 plate_supervisor.py -f plate_cams.txt # spawns N × plate_ws_service.py
# After
python3 plate_multistream_service.py -f plate_cams.txt
plate_supervisor.py still exists for per-camera deployments, but production scale runs one OS process with one shared DeepStream pipeline.
One Pipeline, N Cameras
plate_multistream_service.py replaces the fleet of isolated workers. All enabled cameras connect to one nvstreammux whose batch-size equals the active camera count. A single nvinfer instance loads one TensorRT engine and processes every stream in one batched kernel call.
plate_cams.txt (N cameras)
│
▼
plate_multistream_service.py (single OS process)
│
├── nvurisrcbin × N ──► nvstreammux (batch-size = N)
│ │
│ ▼
│ YOLO TensorRT (one engine, batch = N)
│ │
│ ▼
│ shared probe → OCR queue
│
├── WebSocket + /manual-ocr (cam 1, port from registry)
├── WebSocket + /manual-ocr (cam 2)
└── ...
│
▼
ocr-gpu-v3 (batched Paddle GPU)
At startup, _ensure_pgie_batch_size() rewrites the PGIE config to match the live camera count and points nvinfer at the correct engine file:
batch_size = len(self.pipeline_cameras)
streammux.set_property("batch-size", batch_size)
self.pgie_config_path = _ensure_pgie_batch_size(PGIE_CONFIG_PATH, batch_size)
# → model_b{batch_size}_gpu0_fp16.engine
pgie.set_property("config-file-path", self.pgie_config_path)
For multistream batching to work, the YOLO ONNX must be exported at the target batch dimension (yolo export batch=N dynamic=False). The old batch-size=1 engine cannot be reused — TensorRT compiles maxBatchSize at build time.
What this buys: instead of 20 OS processes, 20 CUDA contexts, and 20 engine copies in VRAM, the fleet shares one inference graph. Kernel launch overhead is paid once per batch interval, not once per camera per frame. GPU utilization drops because the hardware processes meaningful batch work instead of twenty parallel batch=1 threads.
Per-camera WebSocket and /manual-ocr endpoints remain on their registry ports — the manual OCR gateway needs no changes. Each camera gets a CameraRuntime object with isolated state, but they all feed the same GStreamer pipeline.
RTSP sources use nvurisrcbin with automatic reconnect. On first deploy, DEFER_RTSP_UNTIL_PGIE can delay RTSP attachment until the TensorRT engine finishes building — avoiding a long stall where nvstreammux waits for streams that never arrive during engine compilation.
Lazy ROI: PCIe-Friendly Cropping
The old probe copied the full 1920×1080 frame to CPU on every tick. The rebuild moved cropping logic into shared helpers in plate_ws_service.py and made three design choices:
1. CUDA unified memory. nvstreammux, nvvideoconvert, and the decoder use NVBUF_MEM_CUDA_UNIFIED so Python can map GPU buffers without a full PCIe copy:
def map_frame_rgba(gst_buffer, batch_id: int) -> Optional[np.ndarray]:
n_frame = pyds.get_nvds_buf_surface(hash(gst_buffer), batch_id)
return np.asarray(n_frame) # view, not .copy()
2. Metadata-first detection scan. scan_plate_objects() walks NvDsObjectMeta from the YOLO output — no GPU buffer access needed to know where plates are.
3. Lazy frame access. The probe only maps the GPU buffer when a frame is actually needed:
def frame_access_needed(*, first_frame_pending, manual_requested, ocr_candidates) -> bool:
return first_frame_pending or manual_requested or bool(ocr_candidates)
When a plate is detected, only the ROI is converted — not the full frame:
roi = frame_rgba[py:py2, px:px2]
crop = cv2.cvtColor(np.ascontiguousarray(roi), cv2.COLOR_RGBA2BGR)
What this buys: on frames with no plate detection, the probe never touches GPU memory. On detection frames, PCIe traffic scales with crop size (~200×60 pixels) instead of full-frame resolution (~2 megapixels). That is roughly a 30–50× reduction in bytes moved per detection event.
Optional full-frame snapshots for audit (SAVE_FULL_FRAME_ON_AUTO) still convert the whole image, but only when explicitly enabled and only at OCR enqueue time — not on every frame.
OCR Upgrade: Paddle 2.6 → 3.3 (CUDA 13)
OCR was the second half of the GPU contention problem — and it required more than a config change.
The old ocr-gpu-service ran on paddlecloud/paddleocr:2.6-gpu with monolithic PaddleOCR:
PaddleOCR(use_gpu=True, use_angle_cls=True, ...)
ocr.ocr(tmp.name, cls=True) # det → cls → rec, one image at a time
That API had two hard limits:
| Limit | Impact |
|---|---|
| No real GPU batching | ocr.ocr() processes one image per call — no /ocr/batch, no dynamic batch queue |
| Monolithic pipeline | det, angle classification, and recognition bundled together — cannot batch stages independently |
There is no ready-made “PaddleOCR 3.x + batch + GPU” Docker image on Hub. The official paddlepaddle/paddle images ship the framework only; the OCR service layer is custom. We moved to:
paddlepaddle/paddle:3.3.1-gpu-cuda13.0-cudnn9.13
Paddle 3.x exposes separate GPU modules with native batch_size support:
TextDetection(model_name="PP-OCRv4_mobile_det", device="gpu:0")
TextRecognition(model_name="en_PP-OCRv4_mobile_rec", device="gpu:0")
Model inference runs on GPU (device="gpu:0"). JPEG decode and CTC string decode stay on CPU — that is normal and lightweight compared to the neural network forward pass.
Why Not Rec-Only?
The first ocr_service.py prototype sent YOLO crops directly to TextRecognition — skipping detection inside OCR entirely. The logic seemed sound: YOLO already found the plate, so why run det again?
Production testing showed otherwise. YOLO bbox and OCR text box are not the same thing:
DeepStream / YOLO → plate bounding box on full frame
TextDetection → text line box inside the crop
| Test image | Old ocr-gpu-service (det+cls+rec) | v3 rec-only |
|---|---|---|
plate_full_frame.jpg (full plate frame) | 27.ZE 822 (conf 0.88) | 2Z 2 (conf 0.34) |
plate_tight_crop.jpg (tight crop) | good | L27 ZE 822J — artifacts at edges |
Rec-only was fast (~3 ms/image in batch tests) but fragile. YOLO crops often still contain TR strip, frame text, bolt holes, or padding — the recognition model reads the entire bitmap as one line and hallucinates characters.
Sending crops straight to recognition also made us dependent on perfect manual-tight crops. That is risky in a live RTSP pipeline where bbox padding, motion blur, and angle vary per camera.
The production decision: keep TextDetection inside OCR to locate the text region within each YOLO crop, then run TextRecognition on the refined sub-crop. Angle classification (cls) — redundant once the text box is isolated — was dropped. The pipeline became:
YOLO crop → TextDetection batch → largest text poly → sub-crop → TextRecognition batch → plate text
Engine tag in responses: "engine": "modular-det-rec-batch".
Production accuracy matched the old service. Timings below are warmed single requests — the first call after container restart can spike to ~80–90 ms while models load into GPU memory:
| Image | New v3 (modular-det-rec-batch) | Old ocr-gpu-service |
|---|---|---|
plate_sample_2.jpg | 80 ACV730 — 25 ms | 80 ACV730 — 50 ms |
plate_full_frame.jpg | 27ZE822 — ~24 ms | 27.ZE 822 — 46 ms |
plate_tight_crop.jpg | L27 ZE 822J — ~23 ms | — |
On warmed requests v3 was roughly 2× faster than the old service on single crops (~23–25 ms vs ~50 ms). The larger win is fleet throughput when batching kicks in.
Batched OCR: Client and Server
The modular det→rec pipeline runs as two separate GPU batch kernels — not one fused tensor, but both stages batch across N images:
def _run_modular_det_rec_batch(images, langs):
det_out = _get_det().predict(input=images, batch_size=n)
# per image: pick largest detection poly → sub-crop
rec_out = _get_rec().predict(input=crops, batch_size=n)
Two endpoints serve the pipeline:
| Endpoint | Role |
|---|---|
POST /ocr | Single crop — auto-batched by server-side OcrBatcher |
POST /ocr/batch | Explicit multi-crop batch from the DeepStream client |
The server-side OcrBatcher collects concurrent requests within OCR_BATCH_WAIT_MS (default 30 ms) and flushes them as one GPU batch. On the DeepStream side, _ocr_batch_collector gathers crops from the shared OCR queue within OCR_BATCH_COLLECT_MS (default 15 ms) and posts via call_ocr_service_batch():
def _flush_ocr_batch(self, items):
crops = [pws._preprocess_for_ocr(it["image"], it.get("source")) for it in items]
ocrs, err = pws.call_ocr_service_batch(crops)
Manual OCR requests bypass the collector and go straight to POST /ocr — interactive latency stays low.
Batch benchmarks on plate_tight_crop.jpg (N=30):
| Mode | Total time | Per image | Speedup |
|---|---|---|---|
30× batch_size=1 | 222 ms | 7.4 ms | — |
1× batch_size=30 | 94 ms | 3.1 ms | 2.4× |
When twenty cameras fire crops in the same frame interval, the old path queued twenty sequential ~50 ms inferences (~1 s wall time). The new path groups them into one or two GPU batches — amortizing kernel launch across the fleet.
What changed end-to-end:
| Metric | Old (ocr-gpu-service) | New (ocr-gpu-v3) |
|---|---|---|
| Base image | paddlecloud/paddleocr:2.6-gpu | paddlepaddle/paddle:3.3.1-gpu-cuda13.0-cudnn9.13 |
| Inference API | Monolithic PaddleOCR.ocr() | Modular TextDetection + TextRecognition |
| Per-request pipeline | det + cls + rec (sequential) | det + rec (two batched GPU stages) |
| GPU batching | None | predict(batch_size=N) + OcrBatcher + /ocr/batch |
| Upload path | Tempfile on disk | In-memory decode |
| Response fields | inferenceMs | inferenceMs, batchSize, batchInferenceMs, engine |
Operational Compatibility
The rebuild preserved the interfaces operators already relied on:
- Camera registry — same
plate_cams.txtformat (id|name|rtsp|port), with optional per-camera disable flag. - Per-camera ports — WebSocket overlay and
/manual-ocrstay on registry ports; gateway routing unchanged. - OCR response shape —
mergedText,inferenceMs,lines[]— so downstream consumers parse results the same way. - Shared module —
plate_multistream_service.pyimportsplate_ws_service as pwsfor plate normalization, OCR calls, persistence, and crop helpers. Bug fixes in the shared module benefit both deployment modes.
Summary: Old vs New
Old (20 cameras) New (20 cameras)
──────────────── ───────────────
Processes 20 × plate_ws_service 1 × plate_multistream
DeepStream pipelines 20 1
YOLO TRT engines 20 × batch=1 1 × batch=20
nvstreammux batch=1 per process batch=N shared
GPU frame copy Full 1920×1080 every frame ROI only, lazy access
OCR service ocr-gpu-service (Paddle 2.6) ocr-gpu-v3 (Paddle 3.3, det→rec batch)
OCR requests 1 crop → 1 HTTP N crops → 1 batch HTTP
GPU utilization ~94%, no headroom Headroom for burst + growth
The detection architecture from Part 1's target diagram is now what runs in production:
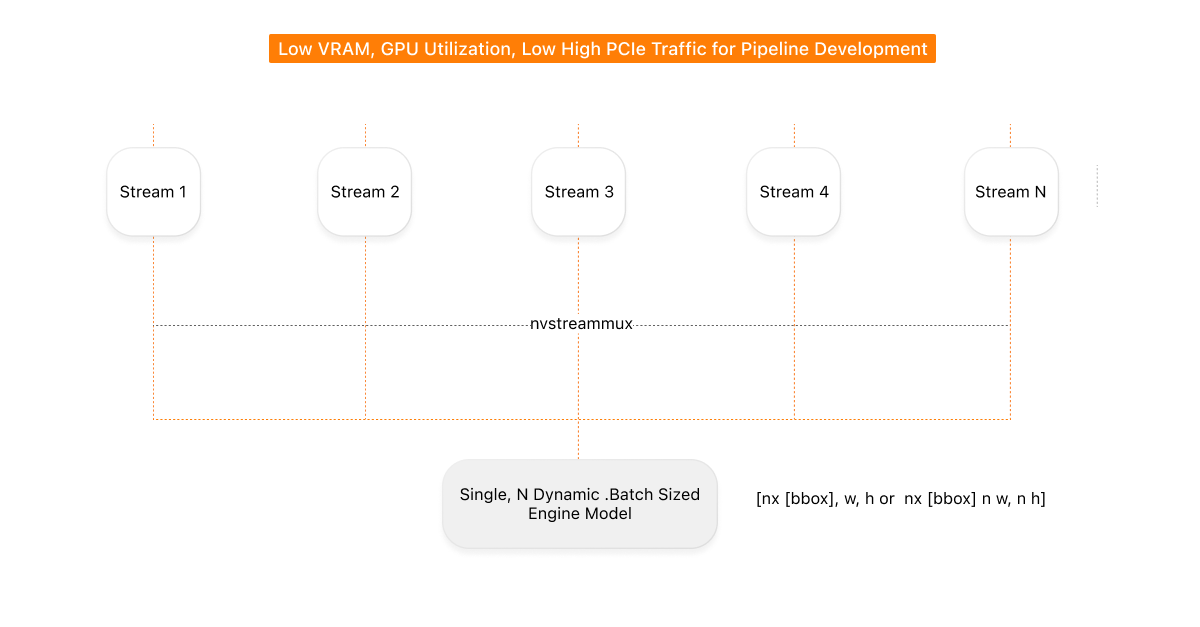
All N streams share one TensorRT engine. Crops leave the GPU path as small ROIs. OCR drains them in GPU batches instead of one HTTP call per plate.
3. Conclusion
The rebuild delivered what the initial architecture could not: easy operations, real scalability, and efficient GPU use across a multistream LPR fleet.
Before this work, the site also relied on traditional CPU-based OCR elsewhere in the stack — slower inference, weaker accuracy on plate crops, and no path to batch twenty concurrent camera events. That approach was adequate for ad-hoc single-image reads; it was not a foundation for industrial video analytics. The new system replaces that model with a GPU-native pipeline: batched YOLO detection in DeepStream, PCIe-friendly ROI cropping, and Paddle 3.x OCR with modular det→rec batching.
The operational gains are concrete:
- One process, one pipeline — camera onboarding stays a single line in
plate_cams.txt; no per-camera process sprawl. - Headroom on the GPU — utilization drops from ~94% pinned to a level that tolerates burst traffic and fleet growth.
- Throughput at scale — OCR crops batch across cameras instead of queueing as isolated HTTP posts.
- Accuracy retained — TextDetection inside OCR compensates for imperfect YOLO crops; results match or exceed the legacy GPU service on warmed requests.
Management is simpler, the architecture scales with camera count, and GPU memory and PCIe bandwidth are spent on work that matters — not on twenty redundant TensorRT engines and full-frame CPU copies.
4. Future Improvements
The current design fits the LPR hot path: JPEG crops over HTTP into a dedicated Paddle GPU service with client- and server-side batching. If the same OCR stack must also serve other workloads — document scans, ad-hoc photo uploads, batch archive reprocessing — a further step is worth considering: NVIDIA Triton Inference Server with dynamic batching and gRPC tensor transport.
Today, even with ROI cropping on the DeepStream side, crops still leave the video pipeline as encoded images and re-enter OCR through HTTP multipart upload. That means JPEG encode on the client, decode on the server, and CPU memory in between. Triton opens a different path:
DeepStream probe → GPU tensor (crop batch)
│
▼
gRPC → Triton (ppocr_det + ppocr_rec, dynamic batch)
│
▼
Text results — no full photo round-trip through CPU RAM
Potential benefits:
| Area | HTTP OCR (current) | Triton gRPC (future) |
|---|---|---|
| Transport | JPEG bytes per crop | Raw or NVMM tensor batch |
| Batching | Application-level collectors | Server-side dynamic batching (preferred batch sizes, queue delay) |
| Multi-tenant OCR | Shared Paddle container | Model repository per stage (det / rec), independent scaling |
| PCIe / CPU | Encode → decode per crop | Tensors stay closer to GPU memory |
This is not required for the LPR fleet that motivated this article — the multistream DeepStream + Paddle 3.x batch service already solved the production bottleneck. Triton becomes relevant when OCR must become a shared inference platform across LPR and other image pipelines, with maximum throughput and minimum CPU involvement in the data plane.
A practical migration path would keep the current HTTP service for backward compatibility while introducing a Triton backend for high-volume batch clients — det and rec as separate ONNX or TensorRT models, dynamic batching on both, and gRPC clients that send preprocessed tensor batches instead of photographs.